Stowers scientists leverage the power of AI to uncover fundamentals of development
08 August 2023
AI models predict the accessibility of chromatin – the DNA/protein complex – from a given sequence of DNA. Model predictions match experimental observations and determine the DNA sequences that are important for opening DNA.
By Rachel Scanza, Ph.D.
The recent rise of ChatGPT has elevated the controversies surrounding artificial intelligence, or AI for short. Is AI a force for good or evil? Will it replace a large percentage of the workforce or serve as a valuable tool to make our lives easier?
Benefits for biological research are clear: AI is undeniably helping scientists analyze data faster, more comprehensively, and in unprecedented detail. A new study from the Stowers Institute for Medical Research, published online in Developmental Cell on August 8, 2023, deployed a form of AI called deep learning to discern early steps in the process of how genes are turned on during animal development.
DNA contains instructions for how an entire animal grows from a single fertilized egg. While it is better known that DNA is organized into units called genes that code for proteins, DNA also contains an enormous amount of regulatory information. This information is read by proteins called transcription factors, which ensure that genes are turned on and expressed into proteins at the right time and in the right place to build tissues and organs.
“These regulatory instructions are absolutely critical for the development of all organisms, but very difficult to decipher,” said Stowers Investigator Julia Zeitlinger, Ph.D. “We are the first to apply deep learning to systematically characterize these rules from embryo data. We took a well-known biological system, the fruit fly embryo, and tested whether AI could learn existing rules of gene regulation during early development. Not only was this successful, but it allowed us to gain an understanding of new rules in the process.”
While some human diseases are caused by mutations in genes, many others arise from mutations in regulatory regions of DNA. Understanding the principles and rules for how genes are regulated could offer insight into the origins of cancers and congenital disorders where gene regulation goes awry.
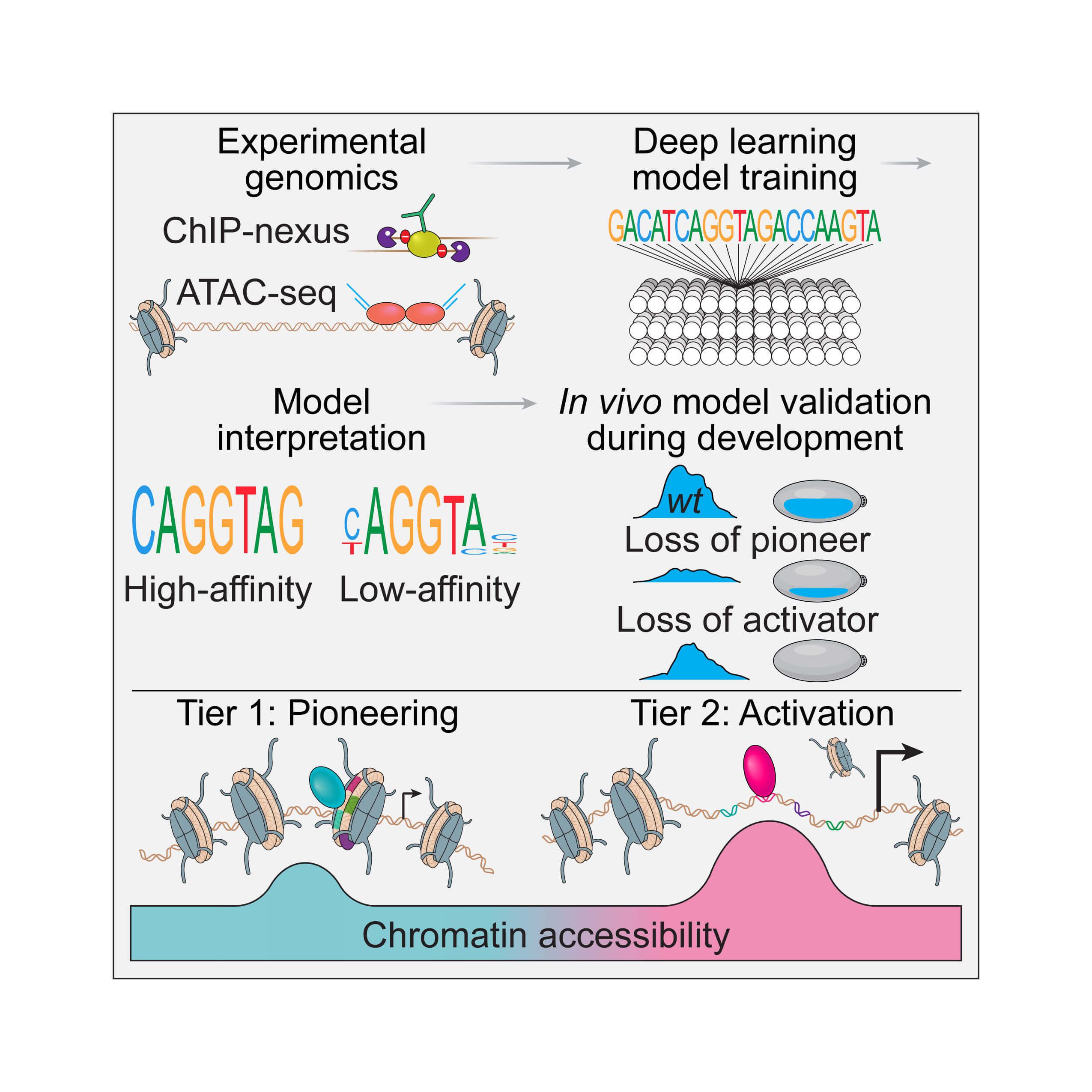
Graphical illustration depicting the process of using experimentally derived data with deep learning to predict regulatory rules of pioneer and non-pioneer transcription factors for the developing fruit fly embryo.
Pioneering development
Led by Predoctoral Researcher Kaelan Brennan and Bioinformaticist Melanie Weilert from the Zeitlinger Lab, the study examined the earliest phase of fruit fly embryo development. This phase is key because the very first cells must decide which parts of the body they will become. Using AI in combination with laboratory experiments, the researchers uncovered that regulatory DNA undergoes a two-step, hierarchical process during these decisions.
The first step in this regulatory process requires a protein called Zelda. Zelda functions as a pioneer transcription factor, which means that it can help the neatly packaged DNA—also called chromatin—to unwrap at specific places. Only after the chromatin is “opened up” can additional transcription factors access and interact with regulatory DNA to then turn on genes.
But while Zelda was already known to open chromatin, the researchers’ results indicated a second step, finding that non-pioneer transcription factors can further enhance access to DNA as genes are being turned on. Together, this two-tier process of gene regulation determines the axes that pattern the fruit fly embryo, helping cells decide their identity as the fruit fly grows.
After investigating chromatin accessibility, the team used imaging experiments to look at the effects of losing both components of the two-tier system, the pioneer and non-pioneer, on the expression of genes important for fruit fly development, sog and tld.
“Uncovering how the second step participates in this two-tier program was a novel finding,” said Brennan. “Zelda, depending on how tightly it binds to chromatin, can open DNA alone. However, the instructions by which the right transcription factors lead to gene activation follow more complex rules that bestow additional DNA accessibility. AI can differentiate both sets of instructions.”
Diving into deep learning
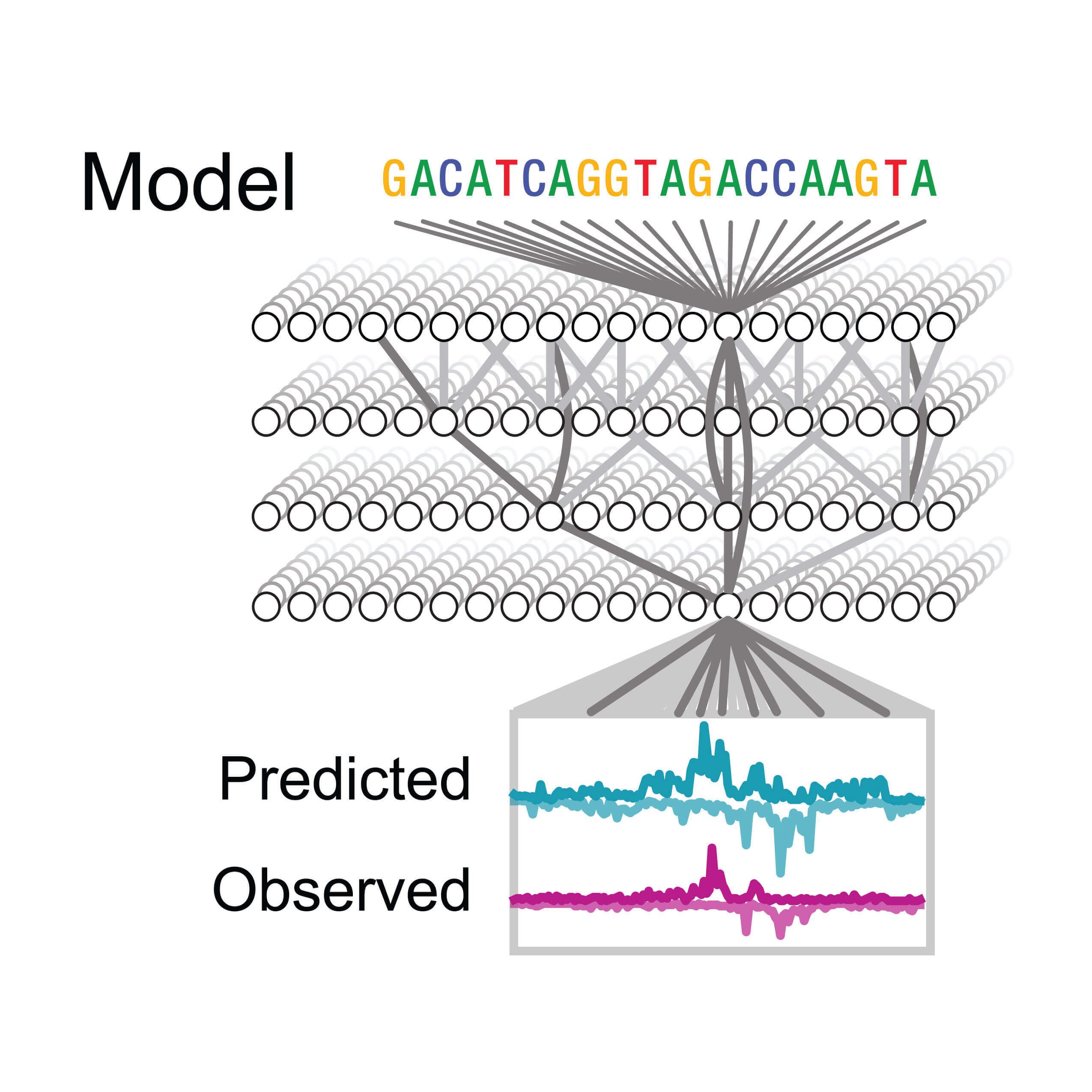
Deep learning models are “trained” to understand the data by iteratively showing them many examples and asking them to predict an answer each time. Over many repetitions, the models eventually learn patterns that help them guess the correct answers. “We train a model on only portions of the data and then test the model on the data it hasn’t seen before to see if it has learned to make accurate predictions,” explained Brennan.
Each regulatory region of DNA has a particular combination and arrangement of sequences that serve as recognition sites for specific transcription factor proteins. The computational challenge for the researchers was to determine which binding sequences in DNA drive the opening of chromatin by transcription factors while simultaneously considering any binding site combination.
To serve as input for deep learning models, the team generated two types of data from lab experiments. One set was associated with chromatin opening while the other corresponded to transcription factor binding. They found that the same simple rules were learned for Zelda from both data sets while the rules for how other transcription factors open chromatin were more difficult to understand.
Thus, the team went back to the lab and performed biochemical, genetics, and genomics experiments to probe the learned DNA sequence rules. These experiments validated the simple rules surrounding the Zelda pioneer transcription factor, showing that its effect on chromatin depends on its binding strength to the sequence.
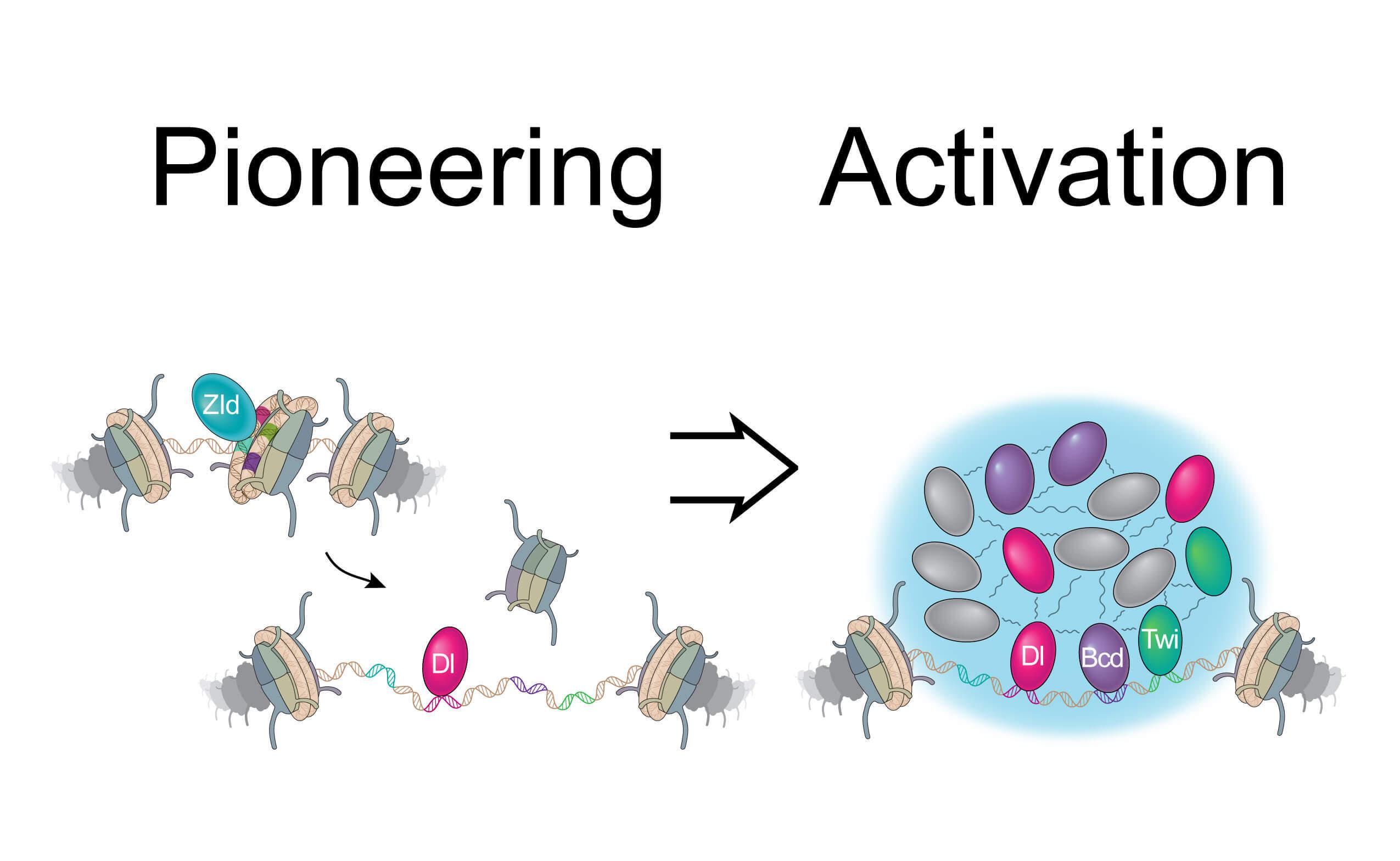
Graphical illustration of the difference between transcription factor pioneering and activation. Zelda (Zld) binds inaccessible DNA, or chromatin, first to enable non-pioneer transcription factors to bind DNA (left). This creates accessibility for binding of the right combination of non-pioneer transcription factors (right) to activate genes during development, which further enhances accessibility.
The experiments also uncovered more complex rules for non-pioneering transcription factors. These non-pioneering proteins need Zelda to access the regulatory DNA, but they can also open chromatin further when they come together in the correct combination. This combinatorial encoding in the DNA is normally associated with the process of gene activation, ensuring that genes are only turned on when the right transcription factors are present. Finding these more complex rules in the chromatin opening data explained why they were more difficult to understand.
“We were able to validate the models in an iterative process,” said Zeitlinger. “We performed experiments, applied deep learning, evaluated the predictions that emerged, and then went back and tested them experimentally.”
Ultimately, the team discovered that while pioneers like Zelda are the first to confer DNA accessibility across the genome, transcription factors also modulate chromatin accessibility during gene activation. This means that the regulatory instructions for opening chromatin and those for activating gene expression are separate but entwined, ensuring the precise regulation of genes during development.
Predictions based on DNA sequence alone
How the researchers predicted pioneering and activation principles of gene regulation during development is changing the game for what biology can achieve with the assistance of AI.
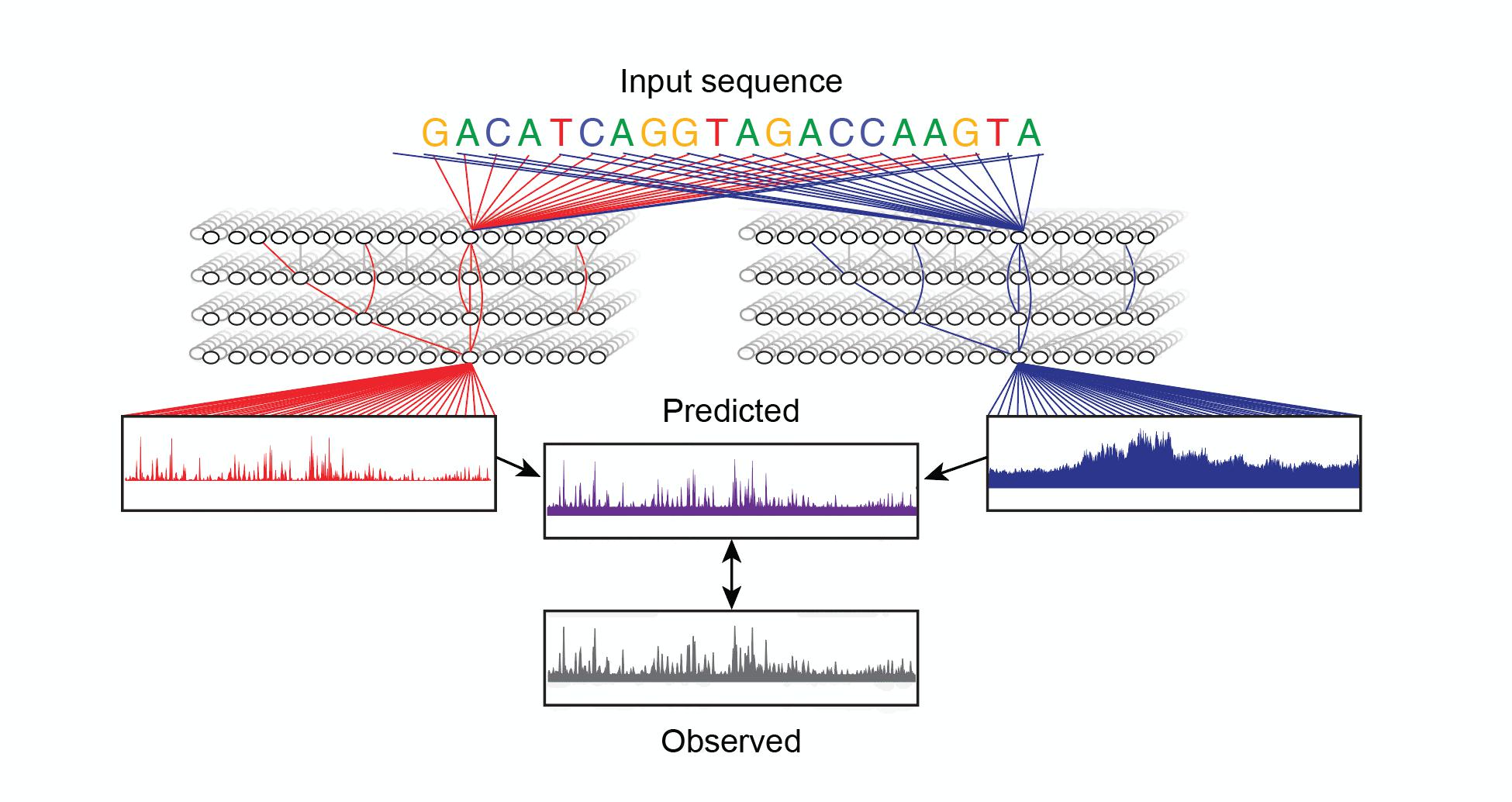
Simple schematic illustrating that deep learning models can predict experimentally observed regulatory rules from DNA sequence alone.
“The models are predicting experimental results based on DNA sequence alone,” said Zeitlinger. “Once the sequence rules are learned, the computer model can read a long stretch of DNA and tell you what the experimental outcome would be. This gets us closer to the Holy Grail—to predict how regulatory elements are governing development simply from DNA sequence.”
“Many diseases in humans are caused by mutations in the regulatory regions of DNA, not just within genes,” explained Brennan. “Studying gene expression and transcription factors helps us understand how this DNA is decoded at the sequence level, which may provide more insight for how mutations in these regions lead to disease.”
Additional authors include Sabrina Krueger, Ph.D., Jason Morrison, Anusri Pampari, Hsiao-yun Liu, Ph.D., Ally W.H. Yang, Ph.D., Timothy Hughes, Ph.D., Christine Rushlow, Ph.D., and Anshul Kundaje, Ph.D.
This work was funded by the Eunice Kennedy Shriver National Institute of Child Health & Human Development of the National Institutes of Health (NIH) (award: F31HD108901) and by institutional support from the Stowers Institute for Medical Research. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.